MySQL 索引
1 为什么使用索引
建立索引的目的就是为了减少磁盘I/O的次数,加快查询效率。索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本字典的目录部分,通过目录找到对应的页码,便可快速找到需要的查找的字或者词语。MySQL中也是一样的道理,进行数据查找时、首先查看查询条件是否命中某个索引、符合则通过索引查找相关数据,如果不符合则需要全表扫描,即需要一条一条地查找记录、直到找到与条件符合的数据。
2 索引及其优缺点
2.1 索引概述
MySQL官方对所有的定义:
索引是帮助MySQL高校获取数据的数据结构索引是在存储引擎中实现的,每种存储引擎的索引不一定完全相同
2.2 优点
- 提高数据检索的效率、降低磁盘IO成本,这也是创建索引最主要的原因
- 通过唯一索引、可以保证数据库每一行数据的唯一性
- 使用分组查询时,显著减少查询中分组和排序的时间,降低CPU的消耗
2.3 缺点
- 创建索引和维护索引要耗费时间、并且随着数据量的增加,耗费时间也会增加
- 索引需要占磁盘空间
- 降低更新表的速度、在对表进行增删改时,同时也会对索引进行动态的维护
3 InnoDB 中的索引B+Tree
InnoDB将数据划分为为若干个页,每个页的默认大小是16kb,页是作为数据库与磁盘交互的基本单位。数据页之间通过双向链表连接。
3.1 索引的演进过程
InnoBD中,索引和数据是存储在一颗B+Tree树(数据存在叶子节点)
- 假如我们创建了一个用户表,字段有id(主键、自增),name,age
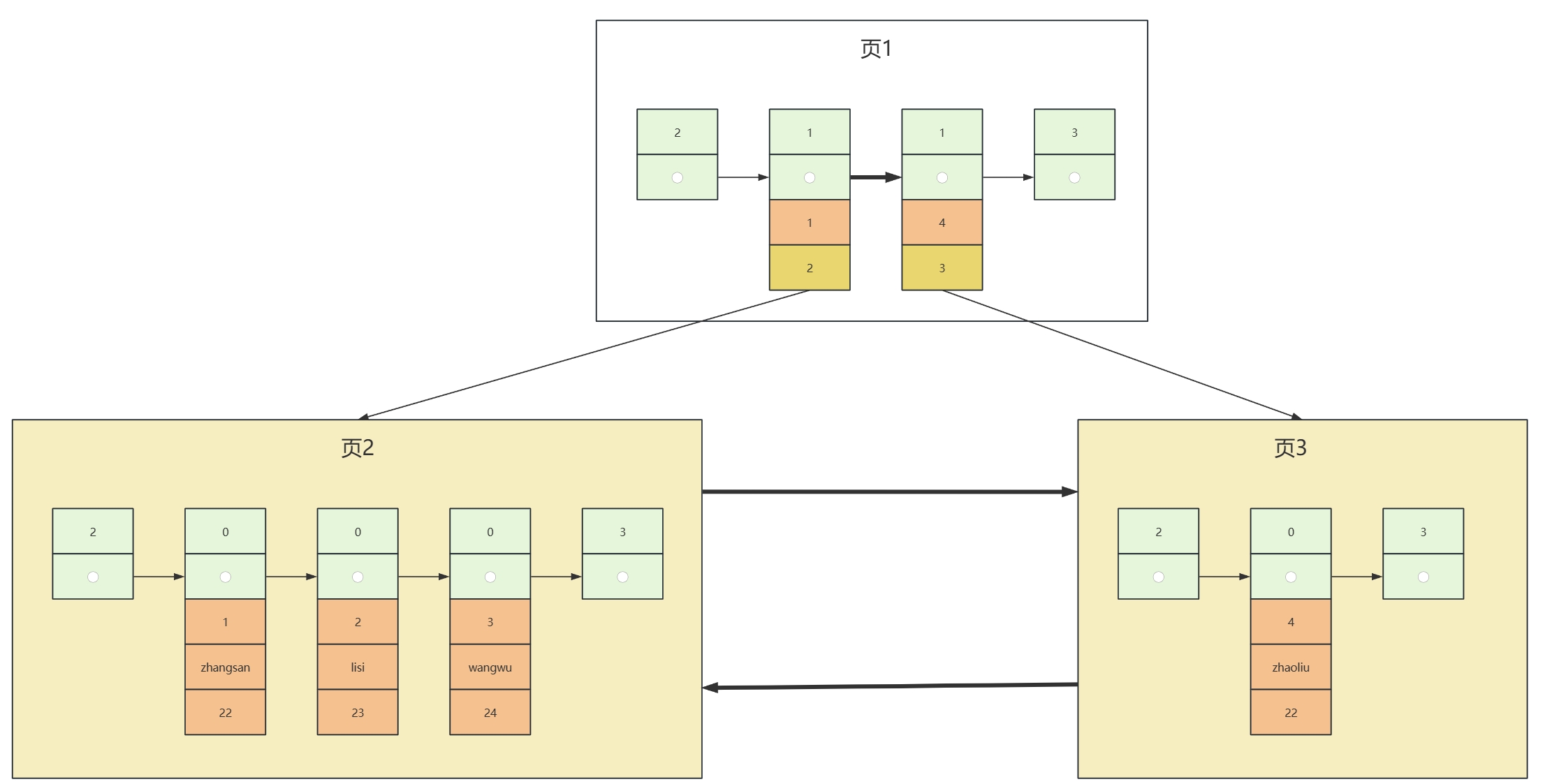
CREATE TABLE `user`(`id` int NOT NULL AUTO_INCREMENT, `name` varchar(20),`age` int,PRIMARY KEY(`id`));- 插入3条数据后,页1的数据大致如下图(这里演示需要,假设每页最多存3条数据)
record_type: 0表示数据、1表示目录、2表示最小值、3表示最大值

- 当再次插入数据时,会发现数据页放不下,则创建一个新的数据页,并将数据赋值到新的数据页上,而自己则变为目录页,不再存放具体的数据,改为存
索引值和数据页的页码。
- 再次插入多条数据,就会变成以下的模型
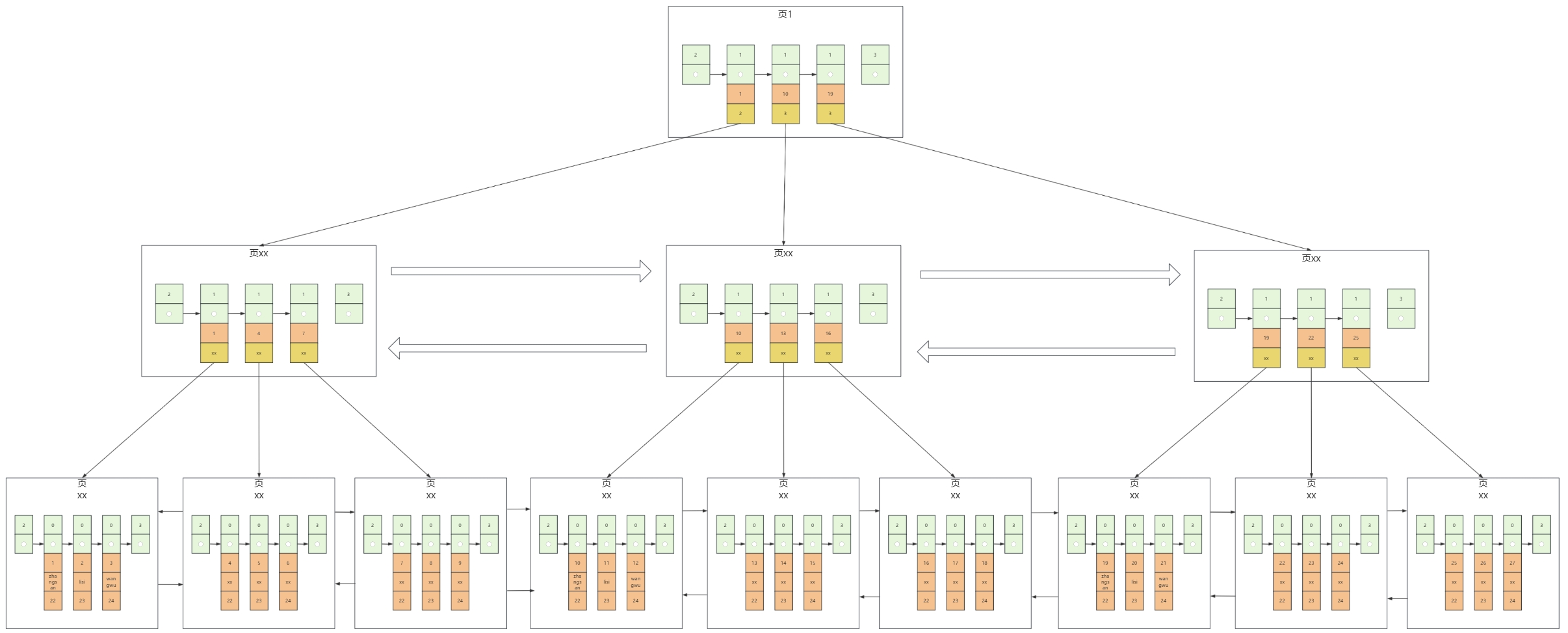
在查询数据时,首先加载目录页,查看索引范围是否符合,符合则进行二分查找,直到命中索引后去加载对应的数据页,数据页加载后再次进行二分查找。这样就显著的减少了IO的操作,提高查询效率。
MySQL的B+Tree结构一般最多不超过4层
以三层索引目录(不含数据页)为例:长整型bigint8字节+数据页码8字节=16字节,以默认的16KB为准,一个目录页大约可以存1000个索引。那么三层的目录页大约可以存1000*1000*1000=1000,000,000个索引
3.1 常见的索引
索引按照物理实现方式,索引可以分为2种:聚簇索引和非聚簇索引。也把非聚簇索引称为额二级索引或者辅助索引。
3.1.1 聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式(所有的记录都存储在了叶子节点),页就是所谓的索引即数据、数据即索引。
"聚簇"表示数据行和相邻的键值聚簇的存储在一起。
特点:
- 使用记录主键值的大小进行记录和页的排序
- 页内的记录时按照主键的大小顺序拍成一个单向链表
- 各个存放记录的页也是根据页中记录的主键大小顺序排成一个双向链表
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录记录主键的大小顺序排成一个双向链表
- B+树的叶子节点存储的时完成的记录(数据)
我们把具有这两种特性的B+树成为聚簇索引,所有完成的记录都存放在这个聚簇索引的叶子节点。这种聚簇索引不需要我们显示的使用INDEX语句去创建,InnoDB会自动的为我们创建聚簇索引(默认主键),如果没有指定主键或者非空唯一索引的情况下,MySQL会隐式的创建一个聚簇索引。
优点:
- 数据访问更快,因为聚簇索引将所有和数据保存在同一个B+树中,因此从聚簇索引获取数据比非聚簇索引更快
- 聚簇索引对于主键的排序查找和范围速度非常快
- 按照聚簇索引排列顺序,查询一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据页中提取数据,节省了大量的IO操作。
缺点:
- 插入的速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将出现页分裂、严重影响性能。因此,对于InnoDB的表,我们一般都会定义一个单调递增的列作为主键
- 更新主键代价很高,会导致被更新行的移动。因此,对于InnoDB,我们一般定义为不可更新。
- 二级索引需要两次索引查询,第一次找到主键值,第二次根据主键值找到行数据(回表操作)
限制:
- 只有InnoDB支持聚簇索引
- 每个MySQL表只有一个聚簇索引,一般情况是主键
- 如果没有主键,InnoDB会选择非空唯一索引代替。如果没有这样的索引,会隐式的定义一个主键来作为聚簇索引。
- 为了充分利用聚簇索引的优势,所以InnoDB表的主键列尽量使用单调递增的id,不建议使用无需的id。比如UUID、MD5、HASH等作为主键,无法保证数据的顺序增长。
3.1.2 非聚簇索引
除了聚簇索引、其他的都是非聚簇索引。同样是一颗B+树,只是叶子节点存储的不是数据,而是索引值和主键值。
3.1.3 InnoDB的B+树的注意事项
- 根页面的位置万年不动。MySQL会默认将根页面加载到内存中
- 每当创建一个B+树索引是、都会为这个索引创建一个根节点。最开始这个节点没有数据。
- 当根节点可用空间用完时,会将根节点的记录赋值到一个新分配的页,然后对这个页进行分裂操作,得到另一个新页,这是新插入的记录根据键值的大小就会被分配到其中一个新页的。根节点升级为目录节点、存储索引值和页码。
- 非叶子节点(内节点)要求目录项记录的唯一性。如果是二级索引、当多个索引值相同时,无法区分数据到底插入到哪一个数据页,所以目录项还要加上主键值。
- 一个数据页最少要存储两条数据
4 MyISAM 的索引B+Tree
MyISAM中是没有聚簇索引的。MyISAM的数据和索引是分开存储,数据和索引是两个文件。
MyISAM将表中的记录按照插入顺序单独存储在一个文件中,称为数据文件。由于在插入时并没有刻意按照大小顺序,所以我们并不能在这些数据上使用二分法查找。
使用MyISAM存储引擎的表会把索引信息另外存储到一个索引文件中。MyISAM对单独为表的主键创建一个索引,只不过在索引的叶子节点中存储的不是完成的记录,而是主键值+数据记录地址。
5 MyISAM和InnoDB对比
- 在InnoDB存储引擎中,我们只需要根据主键值对聚簇索引进行一次查找就能找到对应的记录,而在MyISAM中却需要一次徽标操作,以为着MyISAM创建的都是二级索引
- InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件时分离的。
- InnoDB的非聚簇索引data域存储的相应记录的主键值、而MyISAM存的地址。
- MyISAM的回表操作十分快速,因为是拿着地址偏移量直接到文件中取数据,而InnoDB是通过过去主键后再聚簇索引中找记录,比MyISAM的回表操作稍微慢一点。
- InnoDB要求必须有主键,如果没有,InnoDB会隐式的创建一个主键(6字节,长整型)
6 索引的设计原则
6.1 哪些情况适合创建索引
字段值具有唯一性
频繁作为WHERE查询条件的字段
经常GROUP、ORDER BY的字段
UPDATE、DELETE的WHERE条件
多表JOIN连接索引、需要注意的事项
- 连接表的数量尽量不要超过3张
- 对WHERE条件创建索引
- 对于连接字段创建索引、且连接字段类型保持一致(隐式类型转换可能会不走索引)
DISTINCT字段需要创建索引
使用最频繁的列放在联合索引的左侧
多个字段都需要创建索引时、联合索引优于单字段索引
区分度高(散列性高)的字段适合作为索引
在记录行数一定的情况下、列的基数越大、该列的值约分散;列的基数越小,该列的值就越集中。最好为基数大的字段创建索引,基数太小的列不适合创建索引(比如性别)。
SELECT COUNT(DISTINCT a)/COUNT(*) FROM TABLE 计算,越接近1越好、一般超过33%就是比较高效的索引。
字段值类型小的适合创建索引
在字符串创建索引时,使用字符串前缀索引
6.2 限制创建索引的数目
- 索引不是创建越多越好、索引越多,占用磁盘空间越大
- 索引过多严重影响增删改的性能
6.3 哪些情况不需要创建索引
- WHERE(GROUP、ORDER BY) 条件中使用不到的字段,不要设置索引
- 数据量小的表最好不用索引
- 有大量重复数据的列不要创建索引
- 避免对经常更新的表创建过多的索引
- 不建议用无序的值作为索引
- 不再使用或者很少使用的索引
- 不要定义冗余或重复的索引
6.4 索引失效的情况
- 计算、函数、类型转换导致索引失效
- 联合索引是没有最左侧字段作为条件(按照索引创建的顺序)
- WHERE条件中,范围查询条件后面的条件中的索引失效。(创建索引时、涉及到范围字段的写在最后)
- 不等于(!=、<>)索引失效
- IS NULL 可以使用索引,IS NOT NULL无法使用索引(最好设置字段NOT NULL,设置默认值来代替NULL)
- LIKE 条件以%通配符开头索引失效
- OR 条件前后存在非索引字段
- 字符集不统一、导致字段类型转换索引失效
7 MySQL 索引的语法
7.1 创建唯一索引
CREATE UNIQUE INDEX [INDEX_NAME] ON [TABLE_NAME](col1)7.2 创建非唯一索引
CREATE UNIQUE INDEX [INDEX_NAME] ON [TABLE_NAME](col1)7.3 创建联合索引
CREATE UNIQUE INDEX [INDEX_NAME] ON [TABLE_NAME](col1,col2,col3)7.4 查看表中的索引
SHOW INDEX FROM [TABLE_NAME]7.5 删除索引
DROP INDEX [INDEX_NAME] ON [TABLE_NAME]